
A long-standing goal of 3D human reconstruction is to create lifelike and fully detailed 3D humans from single-view images. The main challenge lies in inferring unknown body shapes, appearances, and clothing details in areas not visible in the images. To address this, we propose SiTH, a novel pipeline that uniquely integrates an image-conditioned diffusion model into a 3D mesh reconstruction workflow. At the core of our method lies the decomposition of the challenging single-view reconstruction problem into generative hallucination and reconstruction subproblems. For the former, we employ a powerful generative diffusion model to hallucinate unseen back-view appearance based on the input images. For the latter, we leverage skinned body meshes as guidance to recover full-body texture meshes from the input and back-view images. SiTH requires as few as 500 3D human scans for training while maintaining its generality and robustness to diverse images. Extensive evaluations on two 3D human benchmarks, including our newly created one, highlighted our method's superior accuracy and perceptual quality in 3D textured human reconstruction.
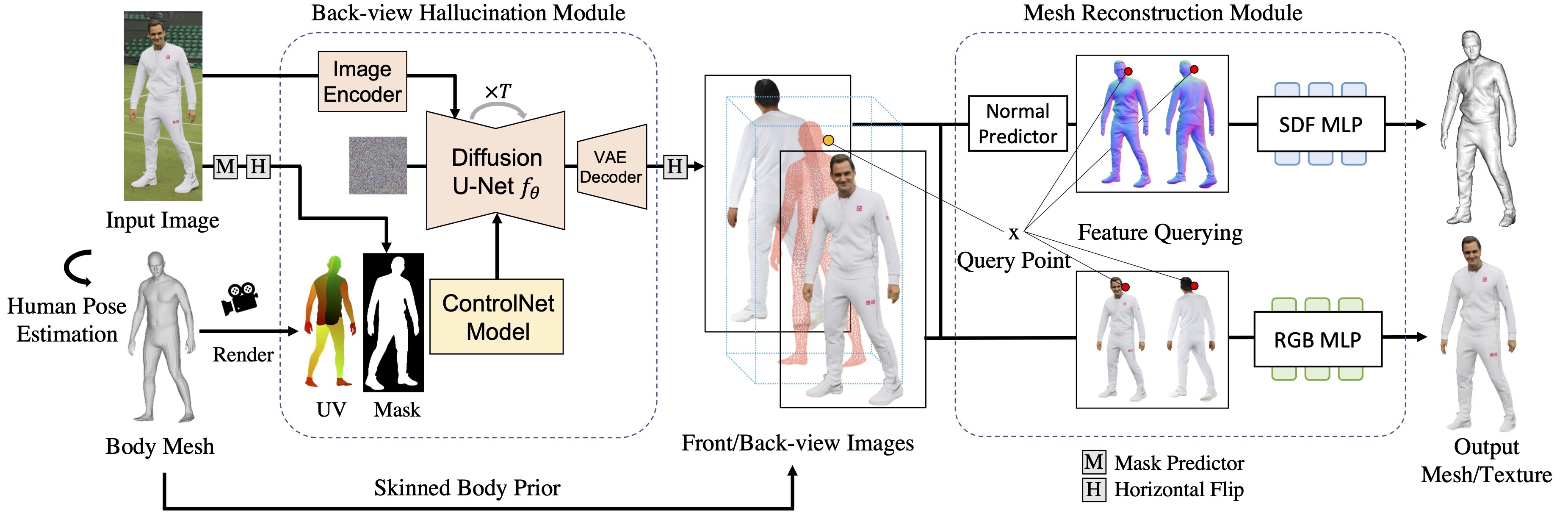
At the core of SiTH is the decomposition of the challenging single-view problem into two subproblems: generative back-view hallucination and mesh reconstruction. For hallucination, we harness the generative capabilities of diffusion models to infer unobserved back-view appearances from the input images. For reconstruction, we utilize a skinned body mesh, providing essential 3D guidance for accurate human mesh reconstruction. This decomposition strategy allows our pipeline to be trained efficiently with just 500 3D scans, while still robustly handling unseen images.
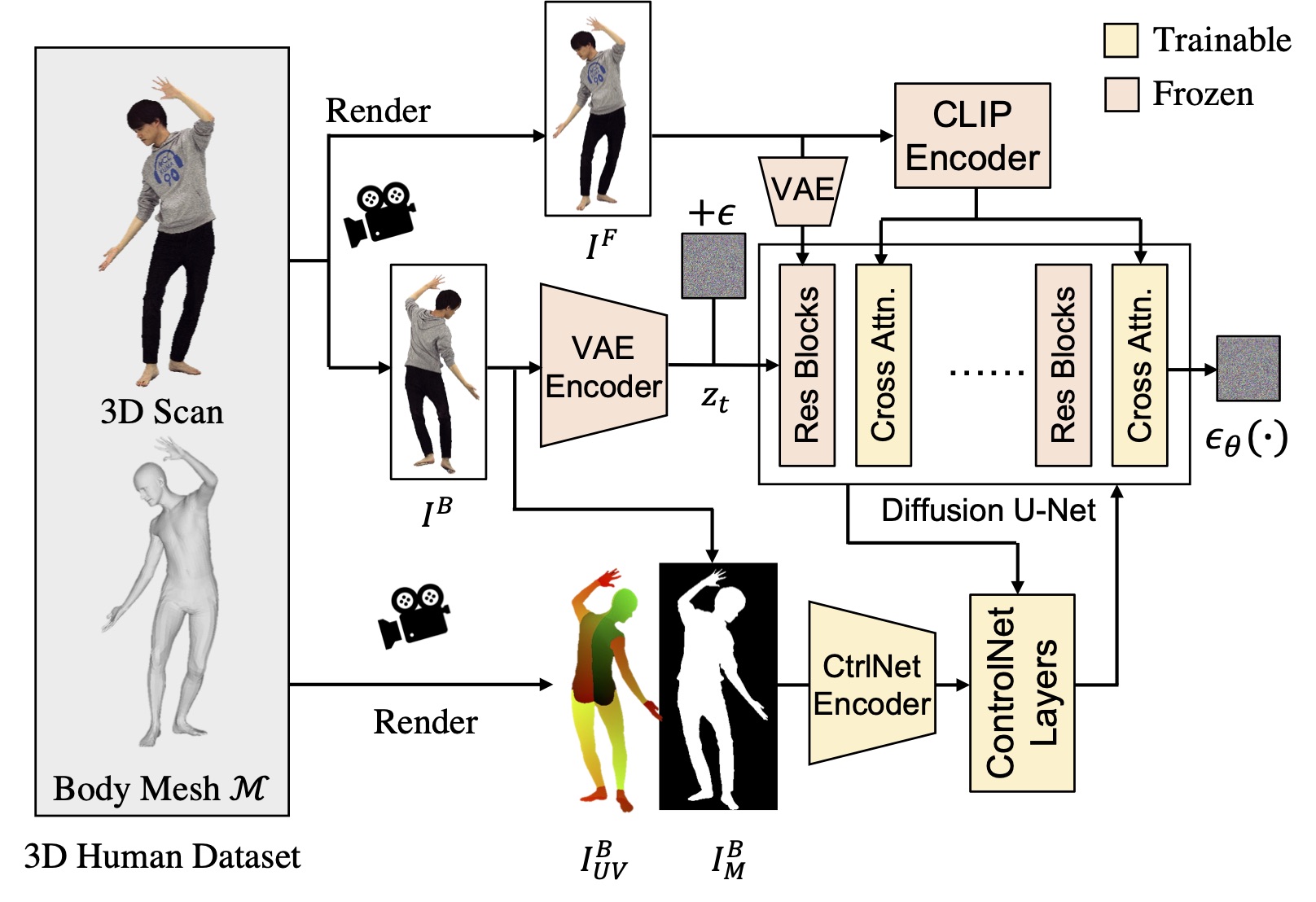
Compared to text-conditioning in traditional diffusion models, our image-conditioning strategy is more consistent and accurate, allowing for building a data-driven 3D reconstruction pipeline. First, the pretrained CLIP and VAE encoders ensure the output images maintain visual consistency with the front-view images. Additionally, we render UV maps from the SMPL-X body mesh and extract silhouette masks from the back-view images. These additional conditional controls ensure the human poses in the output images match those in the front view. To preserve the diffusion model's generative power, we specifically optimize the ControlNet and cross-attention layers with only a small amount of 3D human data.


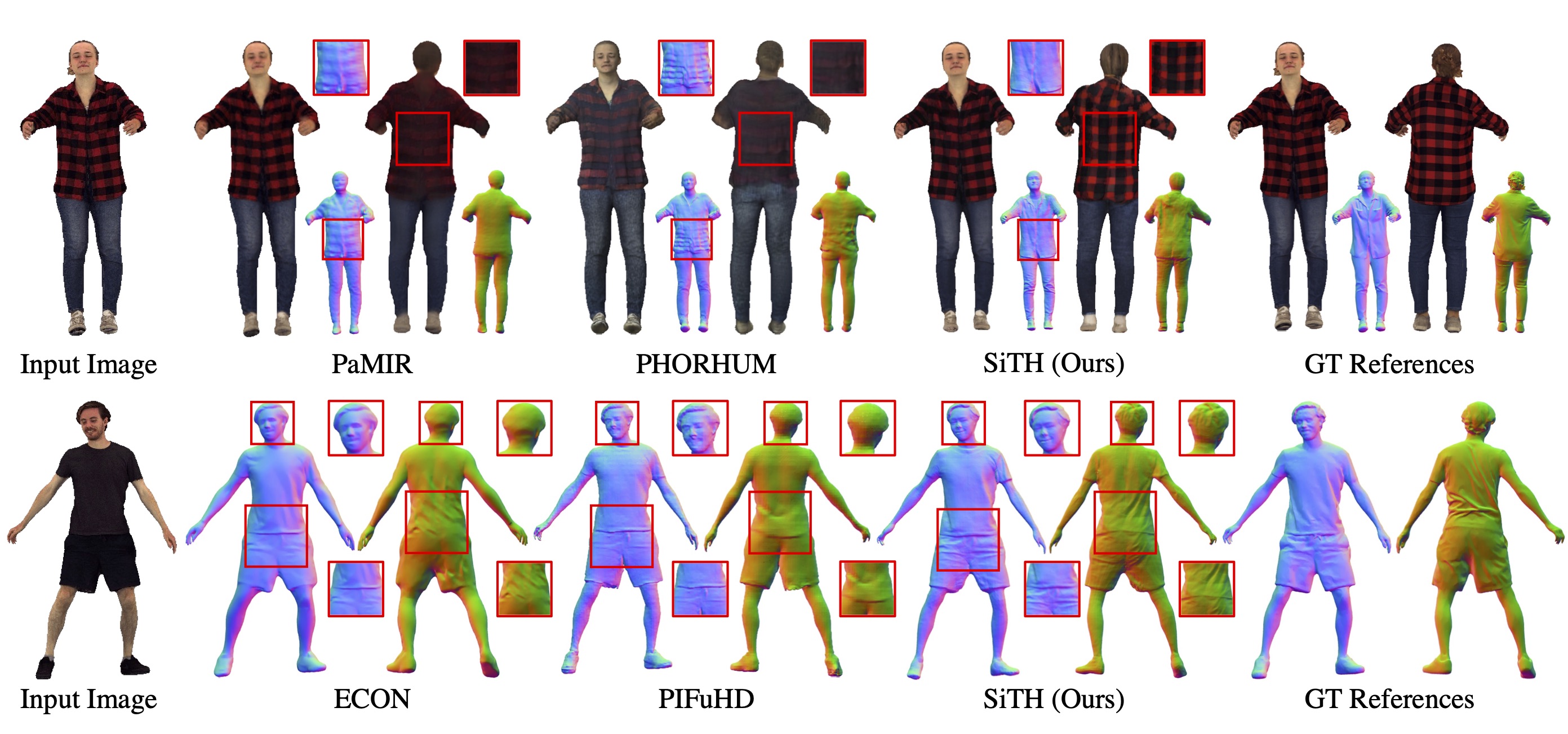
| Methods | P-to-S (cm) ↓ | S-to-P (cm) ↓ | NC ↑ | f-Score ↑ |
|---|---|---|---|---|
PIFu [Saito2019] |
2.209 | 2.582 | 0.805 | 34.881 |
PIFuHD [Saito2020] |
2.107 | 2.228 | 0.804 | 39.076 |
PaMIR [Zheng2021] |
2.181 | 2.507 | 0.813 | 35.847 |
FOF [Feng2022] |
2.079 | 2.644 | 0.808 | 36.013 |
2K2K [Han2023] |
2.488 | 3.292 | 0.796 | 30.186 |
ICON* [Xiu2022] |
2.256 | 2.795 | 0.791 | 30.437 |
ECON* [Xiu2023] |
2.483 | 2.680 | 0.797 | 30.894 |
SiTH* (Ours) |
1.871 | 2.045 | 0.826 | 37.029 |

@inproceedings{ho2024sith,
title={SiTH: Single-view Textured Human Reconstruction with Image-Conditioned Diffusion},
author={Ho, Hsuan-I and Song, Jie and Hilliges, Otmar},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}
This work was partially supported by the Swiss SERI Consolidation Grant "AI-PERCEIVE". We thank Xu Chen for insightful discussions, Manuel Kaufmann for suggestions on writing and the title, and Christoph Gebhardt, Marcel Buehler, and Juan-Ting Lin for their writing advice.








